音声はインターフェースです。これは2025年の音声コミュニティの決定的なメッセージで、今日でも共感を呼び続けています。言語は、人間が身に付ける最初のコミュニケーション・スキルの1つであり、生涯を通じて最も自然なコミュニケーション方法であり続けています。しかし、音声ベースの会話を本当に理解するには、単に音声をテキストに書き起こすだけでは不十分です。NXPでは、人間に自然に期待されるこうした目に見えない社会的なスキルをすべて、人間とのコミュニケーションを目的としたロボット、特にヒューマノイドロボットも習得しなければならないと考えています。
人間は多層的な情報を一度に処理します。感情、ジェスチャー、方向などの視覚的な手がかりを読み取ります。思考の間と話の終わりを区別します。複数話者による会話と発言の順番を管理します。ノイズ、反響、残響をフィルタリングします。また、相手の状況や年齢、外見など、社会的な背景情報に基づいて返答を適応させます。
NXPでは、人間に自然に期待されるこうした目に見えない社会的なスキルをすべて、人間とのコミュニケーションを目的としたロボットも習得しなければならないという認識のもとでソリューションを設計しています。
AIコミュニティは数十年にわたり、キーワード・スポッティング、音声のテキスト変換 (STT)、テキストの音声変換 (TTS) などの基盤となる音声テクノロジを開発してきました。大規模言語モデル (LLM) とビジョン言語モデル (VLM) は、インテリジェント・システムに強力な推論機能を追加しました。最近では、音声言語モデルや音声対話モデルなどの取り組みによって音声と推論のギャップを埋めようとしていますが、今のところ、これらのアプローチではエッジでのロボティクス向けにローカルで信頼性の高い低遅延の対話型AIソリューションを実現するには至っていません。
ロボティクスは、よりインテリジェントになり、エッジで認識して行動するようになることで、この世界を変革しています。Robotics Summit & Expoのブース#536を訪れ、インテリジェントなロボティクスを実現するNXPの最新のソリューションをご覧ください。
実際の状況で対話システムが失敗した場合、通常は、モデルのサイズを大きくしたり、より複雑なプロンプトで補正したりして対処します。しかし、それでは推論の遅延を悪化させ、ユーザー・エクスペリエンスを低下させるだけで、一番の問題である入力音声信号の品質には対処できません。
聞くタイミングを把握するマルチモーダル・インテリジェンス
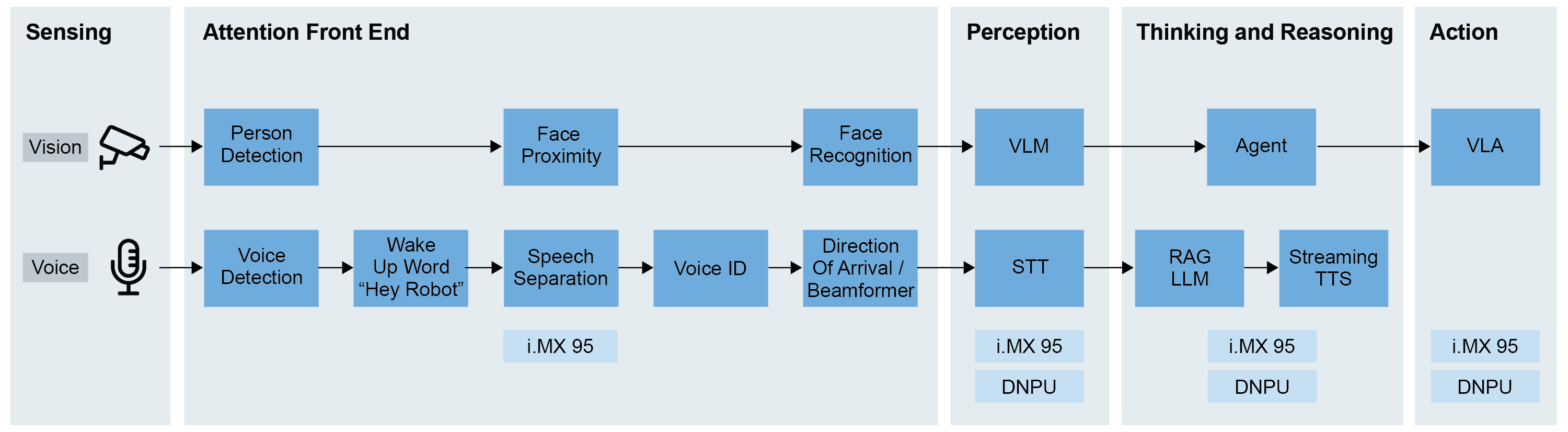 NXPのAttention Front End音声ソリューションの図
NXPのAttention Front End音声ソリューションの図
NXPのAttention Front End (AFE) は、マルチモーダル・センシングと音声信号クリーニングを組み合わせることで、人間とロボットのインタラクションの中核的な課題に対処します。システムは、すべての入力音声を処理するのではなく、ユーザーがロボットに話しかけようとしている意図を検出し、その入力音声を強化して、信頼性が高く、低遅延で、オンデバイスの対話エクスペリエンスをサポートします。追加の利点として、大規模なクラウド・モデルのみに依存する必要がなくなります。
NXPのソリューションは、補完的なモダリティを活用しています。
- ビジョン:状況を分析し、人を検出してカウントし、登録ユーザーを認識し、近接性を推定し、ロボットに向かって話しかける可能性のある人を特定します
- 音声:音声アクティビティを検出し、登録されている声の特徴を識別し、声がどこから届いているかを推定し、音声キャプチャの向きをターゲットの話者に向けます(バックグラウンドでは音響環境の特性評価も行います)
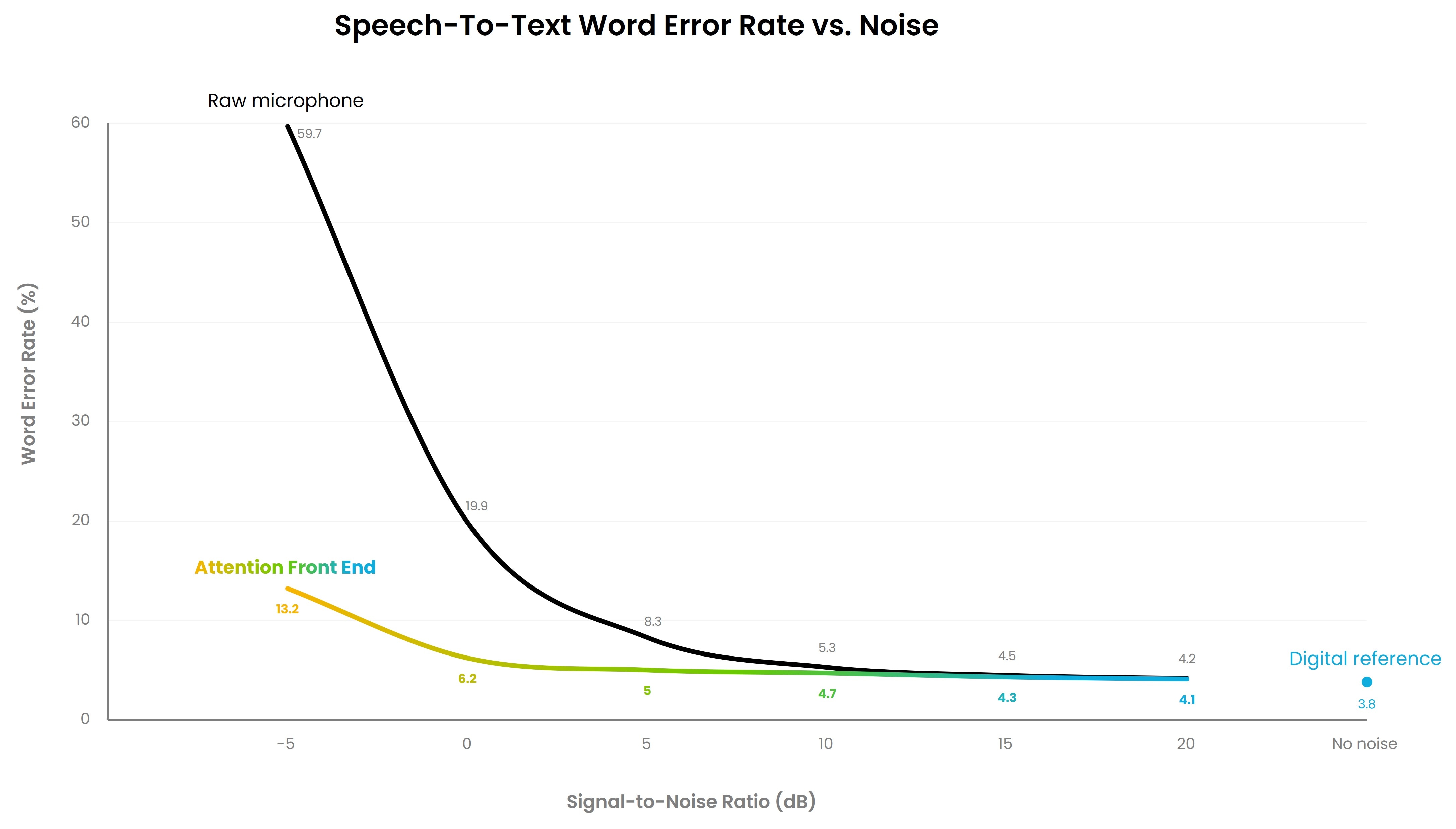
音声のテキスト変換処理は、複数の条件が満たされた場合にのみトリガーされます。それは、ユーザーが視覚的および音響的に識別され、音声が検出され、適切な範囲および方向でインタラクションが起こった場合です。このゲーティング・メカニズムを、NXP内製の音声およびオーディオ・アルゴリズムと組み合わせることで、静かな環境からノイズの多い環境(信号ノイズ比が低い環境など)まで、幅広い条件下で単語誤り率 (WER) が大幅に改善されます。
また、NXPは超広帯域無線(UWB:Ultra-Wideband)テクノロジを統合することで、音声や視覚を超えた空間認識が可能になります。Trimension SR250などのソリューションを使用すると、ロボットはユーザーのスマートフォンや他のロボットのリアルタイム位置を安全に特定し、所有者や仲間がどこにいるのかを把握し、それに応じて対応することができます。UWBは、複雑な環境でも低消費電力と安定した性能を維持しながら、数センチメートル単位の高精度な測距を実現します。この高精度で信頼性の高い位置コンテキストの追加レイヤにより、屋内と屋外の両方のシナリオで、ナビゲーション、インタラクション、および近接に基づいた動作が強化されます。
 NXPのAttention Front Endを統合したBoston Dynamics® Spot®
NXPのAttention Front Endを統合したBoston Dynamics® Spot®
モジュール型設計から測定可能な性能まで
音声のテキスト変換モデル(Whisperなど)のみを使用した場合と比較して、モデルとNXPのAttention Front Endを使用した場合の単語誤り率 (WER) の改善を示す例です。
要約すると、Attention Front Endは、ロボットが人間と同じように耳を傾けるのに役立ちます。つまり、適切な話者に集中し、気を散らすものを無視し、騒々しい環境でも理解できるようにします。ビジョン、音声、近接センサを組み合わせることで、よりクリーンな音声を音声認識モデルに提供し、応答性と精度を向上させながら、エッジでより自然な対話型AIを実現します。
NXPのAttention Front Endは、i.MX 95評価キット (EVK) で評価できます。ソリューションについてご相談がある方、または詳細については、altaf.hussain@nxp.comまでお問い合わせください。